
一般情况下,我并不建议使用自己的IP来爬取网站,而是会使用代理IP。
原因很简单:爬虫一般都有很高的访问频率,当服务器监测到某个IP以过高的访问频率在进行访问,它便会认为这个IP是一只“爬虫”,进而封锁了我们的IP。
那我们爬虫对IP代理的要求是什么呢?
接下来,就讲一下从购买代理IP到urllib配置代理IP的全过程。
代理IP的中间商有很多,我们以无忧代理为例,传送门,点击进入。


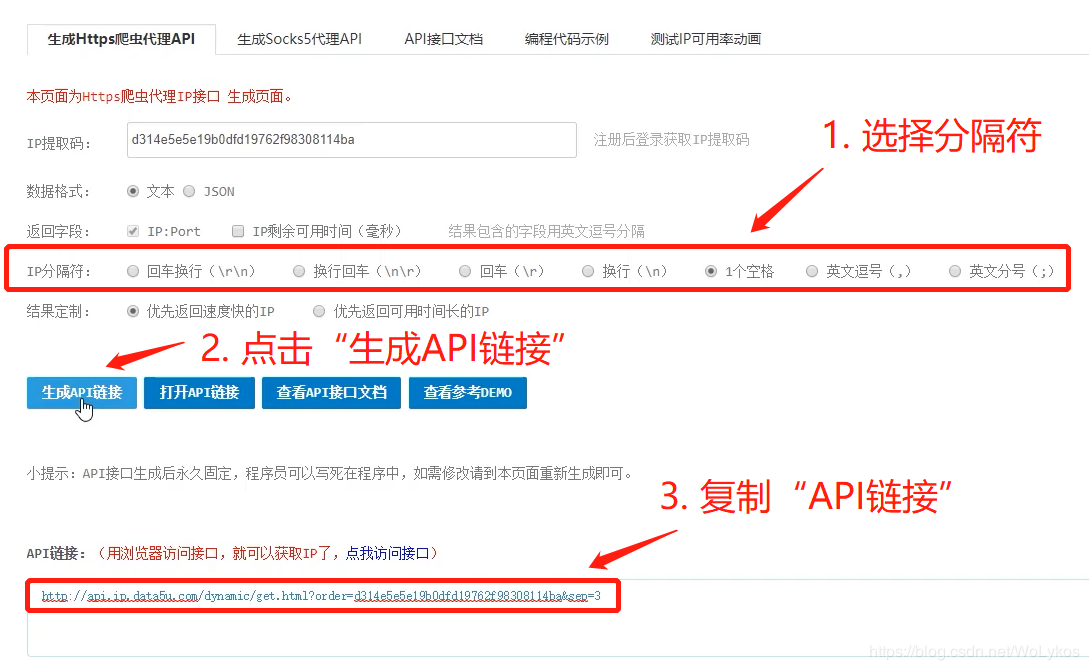
import urllib.request as ur
proxy_address = ur.urlopen('http://api.ip.data5u.com/dynamic/get.html?order=密钥&sep=4').read()
print(proxy_address)
proxy_address = proxy_address.decode('utf-8').strip()
输出如下:
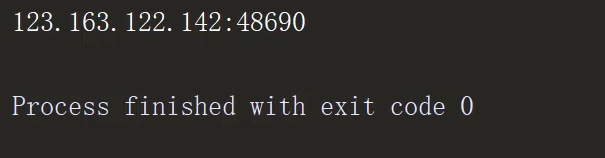
proxy_handler = ur.ProxyHandler(
{
'http': proxy_address
}
)
proxy_opener = ur.build_opener(proxy_handler)
request = ur.Request(url='https://edu.csdn.net/')
# open == urlreponse,只是进行了代理IP封装
reponse = proxy_opener.open(request).read().decode('utf-8')
print(reponse)
输出如下:
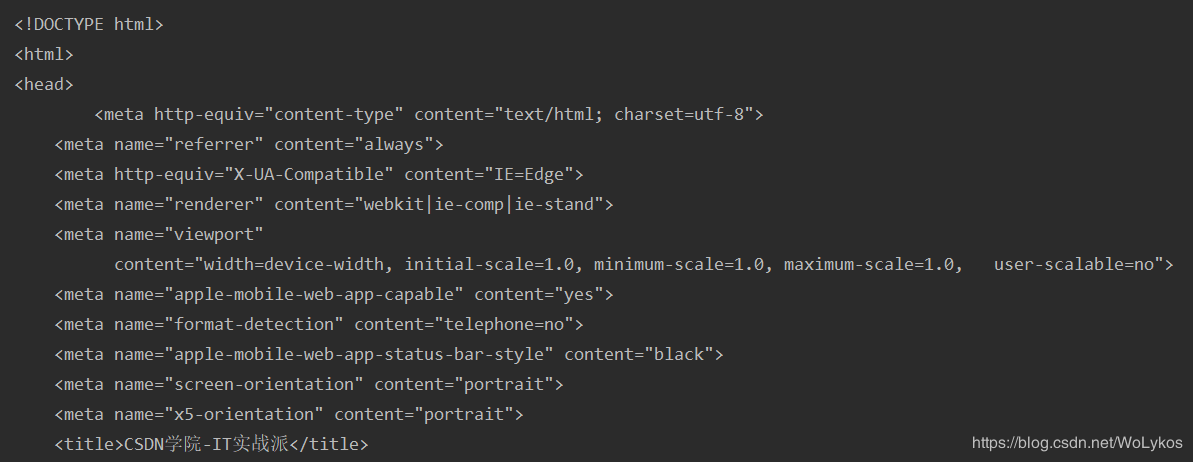
import urllib.request as ur
proxy_address = ur.urlopen('http://api.ip.data5u.com/dynamic/get.html?order=密钥&sep=4').read().decode('utf-8').strip()
# print(proxy_address)
# 创建proxy_handler
proxy_handler = ur.ProxyHandler( {
'http': proxy_address
}
)
# 新建opener对象
proxy_opener = ur.build_opener(proxy_handler)
request = ur.Request(url='https://edu.csdn.net/')
# open == urlreponse,只是进行了代理IP封装
reponse = proxy_opener.open(request).read().decode('utf-8')
print(reponse)